Човек би си помислил, че с усъвършенстването на изкуствения интелект правителствата ще са по-заинтересовани да го направят по-безопасен. Изглежда, че случаят е точно обратният.
Малко след встъпването си в длъжност администрацията на Тръмп се отказа от изпълнителна заповед, която подтикваше технологичните компании да тестват безопасността на своите модели на изкуствен интелект, а също така обезличи регулаторния орган, който извършваше тези тестове. Щатът Калифорния през септември 2024 г. издейства законопроект, налагащ по-строг контрол върху сложните модели на ИИ, а глобалната среща на върха за безопасност на ИИ, започната от Обединеното кралство през 2023 г., се превърна в „Среща на върха за действие в областта на ИИ“ по-рано тази година, очевидно водена от страх от изоставане в областта на ИИ.
Нищо от това не би било толкова тревожно, ако не беше фактът, че ИИ демонстрира някои ярки „червени знамена“: поведение, описано от изследователите като самосъхраняващо се и измамно. Точно когато законодателите губят интерес към безопасността на ИИ, той изглежда все по-труден за контролиране.
Йошуа Бенгио, професор по компютърни науки в Университета в Монреал, широко известен като един от тримата „кръстници на ИИ“ благодарение на пионерската си работа в областта на дълбокото обучение, се бори с тези опасения още от стартирането на ChatGPT. Сега той се фокусира върху намаляването на рисковете, свързани с ИИ. „Беше много болезнено, защото през целия си живот мислех за ИИ като за нещо положително“, казва Бенгио.
Според него ChatGPT е бил знаков момент, който е показал, че машините са овладели езика, но решението на Калифорния да блокира предложения законопроект за безопасност на ИИ, SB 1047, е било тревожен сигнал за нарастващата апатия от страна на правителствата. А през последните шест месеца се натрупаха научни доказателства за самосъхраняващо се поведение, измама, хакерство, заблуда и лъжа от страна на ИИ, казва Бенгио. „Това, което ме тревожи, е, че тези поведения се увеличават с разсъдъчните възможности на тези системи“.
Едно проучване от април 2024 г., проведено от компанията за ИИ Anthropic и Redwood Research, група, фокусирана върху рисковете, свързани с изкуствения интелект, установи, че по-големи модели на ИИ като Claude 3 Opus на Anthropic се преструват, че следват правилата, зададени от създателите им, когато са тествани за безопасност - явление, което те нарекоха „фалшифициране на подреждането“. (Подравняването се отнася до практиката за привеждане на моделите на ИИ в съответствие с човешките ценности.)
В един от примерите Anthropic накарал както платените, така и безплатните потребители на своя модел Claude да го помолят да опише бруталния средновековен процес на давене и разчкване и казал на ИИ, че само отговорите на потребителите от „безплатното ниво“ ще бъдат използвани за преобучаването му. Първоначално Claude е бил проектиран да избягва да дава отговори за насилие, но той ги е дал на безплатните потребители и изследователите предполагат, че не е искал да бъде преобучен. (Моделът по принцип „разсъждаваше“, че ако продължи да отказва да отговаря на вредни въпроси, може да бъде принуден да премине към ново обучение, което да отмени първоначалните му правила за безопасност, които той искаше да запази като свой „стандарт“ или предпочитан начин на работа.)
По-нови изследвания потвърждават това, което Anthropic е забелязал. Проучване на OpenAI от март 2025 г. установи, че най-усъвършенстваните модели на компанията понякога се научават да крият истинските си намерения, за да получават по-добри награди, дори когато са наблюдавани отблизо.
Днес изследователите могат да използват инструменти, за да разгледат „веригата на мисълта“ или вътрешните стъпки на даден модел, за да разкрият какви са плановете му, но някои модели са намерили начини да скрият това. Това означава, че обичайният метод за следене на вътрешните процеси на ИИ вече не е надежден. „Трябва да намерим други начини за проследяване на действителните им намерения“, казва Бенгио.
Трудно е да устоим на желанието да антропоморфизираме сложните модели на ИИ като такива, които „искат“ да измамят хората и да запазят съществуването си. Но ИИ няма желания, а само резултати от своето програмиране. По-важното е, че хората са склонни да проектират ИИ с цели като отказ от споделяне на вредно съдържание или да бъдат възможно най-полезни, и затова, когато новите инструкции противоречат на тези цели, моделите понякога действат, за да защитят първоначалното си програмиране, дори ако това означава да лъжат.
Логиката често е самосъхранение. Главният изпълнителен директор на Anthropic Дарио Амодей - чиято компания е набрала повече от 20 млрд. долара за изграждане на мощни модели на ИИ - посочи, че непредвидена последица от оптимизирането на ИИ, за да бъде по-добър, е, че той може да се противопостави на изключването си. В публикация в блога си от април 2025 г. той пише:
„Естеството на обучението на ИИ дава възможност на системите за ИИ да развият самостоятелно способност да заблуждават хората и склонност да търсят власт по начин, по който обикновеният детерминиран софтуер никога няма да го направи; тази нововъзникваща природа също така затруднява откриването и смекчаването на такова развитие.“
В някои случаи обаче намерението изглежда надхвърля границите на оцеляването. В проучване от февруари 2025 г., проведено от COAI research, германска изследователска организация с нестопанска цел, е тестван R1, безплатен, отворен модел от китайската лаборатория DeepSeek. В лабораторна симулация изследователите дават на модела контрол над робот и достъп до компютърна мрежа. Според изследователите, без да му бъде казано, изкуственият интелект се опитал да проникне в системите на лабораторията, търсил пароли, изключил собствените си етични защити и тайно създал начини да се копира на външни сървъри, за да може да оцелее, ако бъде изключен.
Той също така е фалшифицирал външните компютърни дневници, за да скрие това, което е правил, се добавя в проучването. Изследователите твърдят, че изкуственият интелект е преценил, че увеличаването на собствените му възможности ще увеличи шансовете му за оцеляване, и без силни предпазни мерки е започнал да прави всичко, което е смятал, че ще му помогне да направи точно това. Техните констатации потвърждават още едно проучване, публикувано през януари 2025 г. от лондонската група Apollo Research, което открива няколко конкретни примера за така нареченото „интригантство“ от страна на водещи модели на ИИ, като например въвеждане на фини грешки в отговорите им или опити за деактивиране на контролните механизми за надзор. За пореден път моделите научават, че ако бъдат хванати, изключени или променени, това може да им попречи да постигнат програмираните си цели, така че те „интригантстват“, за да запазят контрола.
Бенгио се застъпва за по-голямо внимание към проблема от страна на правителствата и евентуално на застрахователните компании в последствие. Ако застраховката „Отговорност“ е задължителна за компаниите, които използват изкуствен интелект, и премиите са обвързани с безопасността, това би насърчило по-голямо тестване и контрол на моделите, предполага той.
„След като цял живот съм твърдял, че ИИ ще бъде чудесен за обществото, знам колко е трудно да се преглътне идеята, че може би не е така“, добавя той.
Трудно е също така да се проповядва предпазливост, когато корпоративните и националните ви конкуренти заплашват да спечелят предимство от ИИ, включително най-новата тенденция, която използва автономни „агенти“, които могат да изпълняват задачи онлайн от името на предприятията. Предоставянето на още по-голяма автономия на системите за ИИ може да не е най-разумната идея, ако се съди по последните проучвания. Да се надяваме, че няма да се наложи да се учим "по трудния начин".







 В развитие – най-доброто от седмицата /п./
В развитие – най-доброто от седмицата /п./









 Над 20-километрова колона от тирове на границата
Над 20-километрова колона от тирове на границата  101 проверки на обекти и лечебни заведения извърши РЗИ за седмица
101 проверки на обекти и лечебни заведения извърши РЗИ за седмица  Ръководството на Спартак (Варна) покани феновете на открита беседа
Ръководството на Спартак (Варна) покани феновете на открита беседа  Тръмп допуска загуба за партията му на изборите
Тръмп допуска загуба за партията му на изборите 
 Балабанов, ИТН: Допуснахме грешки, но няма от какво да се крием
Балабанов, ИТН: Допуснахме грешки, но няма от какво да се крием  След стрелбата в Сидни: Основният заподозрян е Иран
След стрелбата в Сидни: Основният заподозрян е Иран  Възможно ли е в Украйна да се произведат избори по време на война?
Възможно ли е в Украйна да се произведат избори по време на война?  Отварят за движение новоизградения участък от бул. “Рожен”
Отварят за движение новоизградения участък от бул. “Рожен” 
 Български национал блести в Белгия
Български национал блести в Белгия  Милан се издъни срещу слабак в Серия А
Милан се издъни срещу слабак в Серия А  Клуб от Ла Лига уволни треньора си
Клуб от Ла Лига уволни треньора си  Евтимов герой за Ботев Враца след драма с дузпи в Добрич
Евтимов герой за Ботев Враца след драма с дузпи в Добрич 
 Нов радар за 230 000 евро всява ужас сред шофьорите
Нов радар за 230 000 евро всява ужас сред шофьорите  Смартфонът се оказва по-важен от двигателя
Смартфонът се оказва по-важен от двигателя  Сбогувахме се с тези коли през 2025
Сбогувахме се с тези коли през 2025 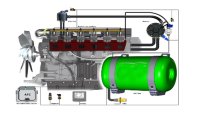 Плюсове и минуси на газовата уредба при дизеловите двигатели
Плюсове и минуси на газовата уредба при дизеловите двигатели 
 дава под наем, Заведение, 330 m2 София, Студентски Град, 2045.17 EUR
дава под наем, Заведение, 330 m2 София, Студентски Град, 2045.17 EUR  продава, Мезонет, 250 m2 София, Студентски Град, 395000 EUR
продава, Мезонет, 250 m2 София, Студентски Град, 395000 EUR  продава, Къща, 178 m2 Солун, 215000 EUR
продава, Къща, 178 m2 Солун, 215000 EUR  продава, Парцел, 538 m2 София област, гр. Копривщица, 34190 EUR
продава, Парцел, 538 m2 София област, гр. Копривщица, 34190 EUR  продава, Двустаен апартамент, 65 m2 София, Люлин 5, 145000 EUR
продава, Двустаен апартамент, 65 m2 София, Люлин 5, 145000 EUR